How to effectively design a relational database schema sets the stage for this enthralling narrative, offering readers a glimpse into a world where data organization meets innovative design. With the rapid growth of data-driven applications, understanding relational databases becomes crucial. This guide will explore the core components of relational databases, detailing the pivotal roles of tables, records, and keys, while embarking on a journey through the steps necessary to create a well-structured schema.
From grasping the fundamental concepts to mastering normalization techniques, the intricacies of schema design will be unveiled. We’ll walk through the essential best practices and tools that empower database designers to create efficient and effective databases, ultimately ensuring seamless data management in any application.
Understanding Relational Database Concepts
Relational databases form the backbone of modern data storage and management systems, providing a structured way to handle vast amounts of information. This architectural style allows for efficient querying, data integrity, and relationship mapping between different data entities, making it essential for applications ranging from simple websites to complex enterprise systems.At the core of a relational database are tables, records, and fields.
Tables are the primary structure used to organize data; they consist of rows and columns. Each row, known as a record, represents a unique entry within the table, while each column, referred to as a field, defines a specific attribute of the data being stored. This tabular format allows for easy organization and retrieval of information, supporting complex queries that can filter, sort, and aggregate data as needed.
Role of Primary and Foreign Keys
The effectiveness of a relational database is greatly enhanced by the use of primary and foreign keys, which are vital for establishing and maintaining relationships between tables. Primary keys uniquely identify each record within a table, ensuring that there are no duplicate entries. This uniqueness is crucial for maintaining data integrity and facilitating efficient searches.Foreign keys, on the other hand, are fields in a table that create a link between two tables.
They reference the primary key of another table, establishing a relationship that allows for data to be connected and retrieved across different entities. The use of primary and foreign keys is essential for:
- Data Integrity: Ensuring that relationships between tables remain consistent, preventing orphaned records and maintaining the accuracy of data.
- Efficient Querying: Enabling complex data retrieval operations that can pull related information from multiple tables seamlessly.
- Normalization: Assisting in the process of organizing data to reduce redundancy and improve data integrity through well-defined relationships.
In summary, understanding the fundamental concepts of relational databases, particularly the roles of tables, records, fields, primary keys, and foreign keys, is crucial for effective database design. This knowledge equips developers with the tools to create robust, scalable applications that can handle data in a structured and efficient manner.
Steps to Design a Relational Database Schema
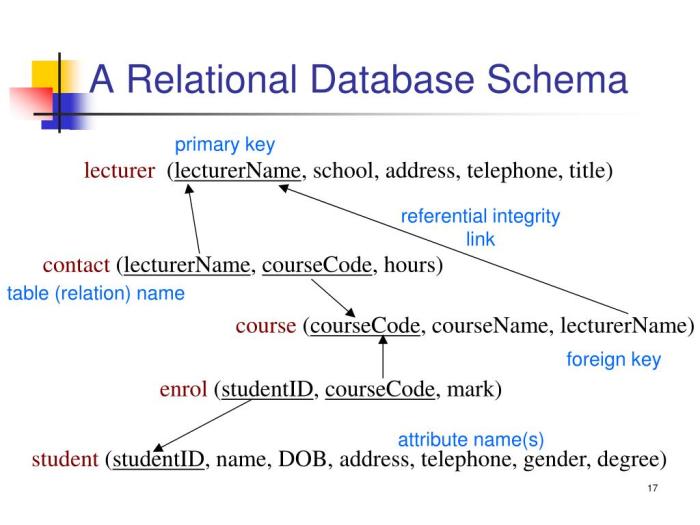
Designing a relational database schema requires careful planning and a structured approach. The effectiveness of a database largely depends on how well it meets user requirements and the clarity of its structure. This section Artikels essential steps in the design process, including gathering requirements, creating an entity-relationship diagram, and defining tables and relationships.
User Requirements Identification
The first step in designing a relational database schema is to thoroughly understand the needs of the users. This involves gathering and documenting the requirements that the database must fulfill.
Stakeholder Interviews
Conduct interviews with end-users and stakeholders to capture their needs and expectations. This helps in understanding the data they interact with and the functionalities they require.
Use Cases
Develop use cases that Artikel different scenarios in which users will interact with the database. This helps in identifying specific data needs and workflows.
Requirement Analysis
Analyze the collected information to identify common themes and requirements. Group similar requirements together to streamline the design process.
Documentation
For businesses aiming to enhance their database performance, Understanding the importance of database indexing for speed is key. Proper indexing can dramatically reduce query response times, allowing for faster data retrieval. This optimization not only boosts system performance but also significantly enhances user satisfaction by ensuring that information is readily accessible.
Maintain clear documentation of all user requirements for future reference and validation.Gathering user requirements is crucial as it lays the foundation for the database design, ensuring it aligns with user needs and expectations.
In today’s competitive landscape, understanding how to leverage big data in business intelligence is crucial. By analyzing large volumes of data, businesses can uncover actionable insights that drive strategic decision-making, optimize operations, and enhance customer experiences. This data-driven approach not only improves efficiency but also positions companies to adapt swiftly to market changes.
Creating an Entity-Relationship Diagram (ERD)
An Entity-Relationship Diagram (ERD) serves as a visual representation of the data model and is vital for database design. This diagram illustrates entities, attributes, and relationships, providing a clear overview of the schema.
Identify Entities
Begin by identifying the key entities relevant to the system. Entities typically represent real-world objects or concepts relevant to the business.
Define Attributes
For each entity, list its attributes, which are the specific data points that need to be stored. For example, a “Customer” entity may have attributes like CustomerID, Name, and Email.
Establish Relationships
Determine how entities are related to each other. Define the types of relationships, such as one-to-one, one-to-many, or many-to-many.
Draw the ERD
Utilize diagramming tools to visualize the entities, their attributes, and the relationships. Ensure clarity and simplicity in the diagram to facilitate understanding.An ERD is not just a planning tool; it serves as a guide for how the database structure will emerge, ensuring that all required elements are included.
Defining Tables and Relationships
Once the ERD is prepared, the next step is to translate this diagram into a structured database schema by defining tables and establishing relationships.
Table Creation
Each entity identified in the ERD corresponds to a table in the database. Create tables with appropriate names and define the primary key for each table to ensure uniqueness.
Attribute Specification
Populate each table with the attributes identified in the ERD. Define data types for each attribute, such as INTEGER, VARCHAR, DATE, etc.
Setting Relationships
Specify foreign keys in the tables to establish relationships. Foreign keys should reference primary keys from related tables, thus enforcing referential integrity.
Normalization
Apply normalization techniques to minimize redundancy and ensure data integrity. This involves organizing the fields and tables of a database to reduce dependency and redundancy.By meticulously defining tables and their relationships, the database schema will be robust, facilitating efficient data management and retrieval.
Normalization Techniques
Normalization is a fundamental concept in database design that aims to organize data in a way that reduces redundancy and improves data integrity. The purpose of normalization is to structure a relational database schema in a way that ensures logical data storage and retrieval, thus minimizing data anomalies during updates, deletions, and insertions.Normalization involves decomposing a database schema into smaller, more manageable tables without losing the relationships among the data.
This process is categorized into several levels known as normal forms, with each subsequent form addressing specific types of redundancy and dependency. The most commonly applied normal forms in database design are the First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF).
First Normal Form (1NF)
To achieve First Normal Form, a table must meet the following criteria:
- Each column must contain atomic values, meaning each field should hold indivisible data.
- Each column must contain values of a single type.
- Each record must be unique, typically ensured by a primary key.
An example of a table that is not in 1NF might include a “Customer” table where a customer’s phone numbers are stored in a single column as a comma-separated list, such as “123-4567, 987-6543”. To convert this into 1NF, the table should be restructured to have a separate row for each phone number, resulting in multiple entries for the same customer.
Second Normal Form (2NF)
Achieving Second Normal Form builds on the requirements of 1NF and requires that:
- The table is in 1NF.
- All non-key attributes are fully functionally dependent on the primary key.
This means that any attribute must depend on the entire primary key, not just part of it. For example, consider a “Course Enrollment” table with a composite primary key consisting of “StudentID” and “CourseID.” If the table also includes a “CourseName” field, which depends only on “CourseID,” then the table is not in 2NF. To normalize this, the “CourseName” should be moved to a separate “Courses” table, linking it back via “CourseID.”
Third Normal Form (3NF)
To achieve Third Normal Form, the table must:
- Be in 2NF.
- Have no transitive dependencies between non-key attributes.
This means that no non-key attribute should depend on another non-key attribute. For instance, in a “Student” table that includes “StudentID,” “AdvisorID,” and “AdvisorName,” the “AdvisorName” is dependent on “AdvisorID,” thus creating a transitive dependency. To convert this into 3NF, “AdvisorName” should be placed into a separate “Advisors” table, thus eliminating the dependency and enhancing data integrity.In summary, normalization techniques play a critical role in ensuring that a relational database schema is efficient, reduces redundancy, and maintains data integrity.
By understanding and applying 1NF, 2NF, and 3NF, database designers can create schemas that are not only functional but also scalable and easier to maintain.
Best Practices for Schema Design
When designing a relational database schema, adopting best practices is critical to ensure efficiency, maintainability, and scalability. A well-structured schema not only improves data integrity but also enhances performance. This segment emphasizes key considerations, including naming conventions, indexing strategies, and common pitfalls that can hinder schema effectiveness.
Naming Conventions for Tables and Fields
Establishing a consistent naming convention for tables and fields is fundamental in relational database design. The choice of names can significantly impact readability and maintenance of the database. Here are essential guidelines for creating effective naming conventions:
- Use Descriptive Names: Table and field names should clearly describe their content. For example, use ‘Customer’ instead of ‘Cstmr’ for a table that stores customer data.
- Maintain Consistency: Apply a uniform naming pattern throughout the database. If using camelCase for one table, apply it to all others.
- Avoid Reserved Words: Steer clear of using SQL reserved s as names to prevent confusion and potential errors.
- Utilize Singular Nouns for Tables: Name tables using singular nouns (e.g., ‘Product’ instead of ‘Products’) to reflect the entity represented.
- Prefix for Specific Context: Consider using prefixes or suffixes to indicate the purpose, like ‘tbl_’ for tables or ‘fk_’ for foreign keys.
Importance of Indexing and Performance Optimization, How to effectively design a relational database schema
Indexing is a pivotal aspect of relational database schema design that significantly influences query performance. Proper indexing can drastically reduce the time taken to retrieve data, leading to a more responsive application. Here are key points regarding indexing strategies:
- Choose the Right Index Type: Understand the different types of indexes (e.g., unique, composite, full-text) and select the one that aligns with your query requirements.
- Index Frequently Queried Columns: Focus on indexing columns that are often used in search conditions, join conditions, or as foreign keys.
- Avoid Over-Indexing: While indexes improve retrieval speed, too many can lead to degraded performance during insert and update operations. Aim for a balanced approach.
- Regularly Monitor and Optimize: Use database performance monitoring tools to analyze query performance and adjust indexes as necessary to ensure optimal efficiency.
Common Pitfalls in Schema Design
Awareness of common pitfalls can prevent costly mistakes during schema design, ensuring a robust and scalable database. Below are typical issues that designers face:
- Neglecting Relationships: Failing to define relationships between tables can lead to data redundancy and inconsistency.
- Ignoring Data Types: Using inappropriate data types for fields can result in inefficient storage and performance issues. Ensure proper data type selection for the specific use case.
- Lack of Documentation: Not documenting schema designs and relationships can create challenges in maintenance and onboarding new team members.
- Overcomplicating Schema: Creating overly complex schemas with too many interdependencies can complicate data retrieval and increase the likelihood of errors.
Adopting best practices in schema design not only streamlines database operations but also lays a solid foundation for future scalability and maintainability.
Tools and Technologies for Database Design: How To Effectively Design A Relational Database Schema
In the realm of database design, selecting the right tools and technologies is crucial for creating a robust relational database schema. These tools not only streamline the process but also enhance collaboration among team members, ensuring that the final design meets both technical and business requirements.Various tools are available that cater to different aspects of database design. Understanding their features and capabilities allows designers to choose the most suitable one for their needs.
The following sections detail popular tools and technologies, focusing on their functionalities and advantages.
Popular Tools for Designing Relational Database Schemas
An array of tools exists for designing relational database schemas, each offering unique features that cater to specific needs. Here is a list of some of the most widely used tools in the industry:
- MySQL Workbench: A powerful visual database design tool that integrates SQL development and database administration, ideal for MySQL databases.
- Oracle SQL Developer Data Modeler: Offers comprehensive modeling capabilities, enabling users to create logical, relational, and physical data models.
- Microsoft Visio: While primarily a diagramming tool, it supports database modeling with templates for ER diagrams.
- DbSchema: A universal database design tool that supports various databases and offers features such as schema synchronization and documentation generation.
- ER/Studio: A robust data modeling tool focused on enterprise-level database design, providing comprehensive modeling and governance capabilities.
Comparison of Database Management Systems (DBMS) for Schema Development
When it comes to schema development, various database management systems (DBMS) provide distinctive features that cater to different design needs. Below is a comparative discussion highlighting key attributes of popular DBMS used for schema development:
| DBMS | Primary Features | Use Cases |
|---|---|---|
| MySQL | Open-source, high performance, strong community support. | Web applications, e-commerce platforms. |
| PostgreSQL | Advanced features like JSONB support, extensibility, strong compliance with SQL standards. | Complex applications requiring data integrity. |
| Microsoft SQL Server | Robust security, integration with Microsoft applications, excellent tools for reporting and analytics. | Enterprise applications, business intelligence solutions. |
| Oracle Database | High availability, comprehensive security options, extensive toolset for data management. | Large-scale enterprise applications, mission-critical systems. |
Advantages of Using Visual Database Design Tools
Visual database design tools provide significant benefits that enhance both the effectiveness and efficiency of database schema development. These advantages include:
- Enhanced Clarity: Visual representations of database schemas make it easier to understand relationships and data flow, reducing misunderstandings among team members.
- Streamlined Collaboration: These tools often facilitate teamwork by allowing multiple users to work on the same schema and share feedback in real-time.
- Automated Documentation: Many visual design tools automatically generate documentation, making it simpler to maintain and update database schemas over time.
- Error Reduction: By providing a visual overview, these tools help identify potential issues early in the design process, thus minimizing costly errors.
- Integration Capabilities: Visual design tools frequently integrate with various database management systems, allowing for seamless implementation of the designed schema.